WordPilot has been one of my most ambitions projects. Although I had plans to monetize it, and actually got to the point of integrating Stripe, I never released it as OpenAI made a product (ChatGPT canvas) which is very similar and more effective.
Functionalities
WordPilot aimed to seamlessly enhance Word documents using AI, preserving their original styling—a feature still missing in ChatGPT Canvas and other tools. Users could drop in a document, and the AI would suggest edits, modify content, or add elements like tables directly within the file, eliminating the hassle of copy-pasting.
Challenges
Handling Word documents in Node.js was a significant hurdle. Existing libraries were poorly documented, requiring me to build custom solutions, including integrity checks, from scratch. It was a steep learning curve, but an invaluable experience in tackling complex technical challenges.
Working with Docx
When a document is uploaded, I first verify its integrity. Since .docx files are compressed archives, I load the file buffer into a ZIP handler to ensure all necessary files for interpretation are present.
The file is then temporarily stored in a Google Cloud bucket, with its status and costs tracked in a Firestore document. Ideally, I would replace "magic strings" with Firebase Remote Config for better maintainability, but with the project discontinued, further improvements aren’t planned.
// Make sure the docx is integrous
await checkDocxIntegrity(file.data) // Throws an error if it is not
// Store the file in a Google Cloud Bucket
const path = `pilot/preprocessed/${docRef.id}`
const fileRef = storage.file(path)
await fileRef.save(file.data)
await updatePilotSession(docRef.id, { preprocessedFilePath: path })
await setStatusMessage(docRef.id, "Calculating tokens")
const documentXml = await docxToXml(file.data, DocxContent.DOCUMENT)
const documentJs = xmlToJs(documentXml)
const documentElements = filterElementsByType(documentJs.elements, "w:p")
const enc = encoding_for_model("gpt-4-1106-preview")
const tokens = documentElements
.map(el => enc.encode(el.text as string)?.length)
.reduce((a, b) => a + b)
const cost = tokens / 1000 * config.gptRate // gpt-4 costs
await updatePilotSession(docRef.id, { estimatedCost: cost, status: "done" })
To accelerate document processing, I implemented batch processing, allowing multiple paragraph batches to be processed simultaneously. Each batch was enriched with context to help the AI deliver more accurate and relevant results.
const paragraphsWithContext = createContext(markdownElements, { size: contextSize });
setStatusMessage(docRef.id, `Analyzing ${markdownElements.length} paragraphs`);
// Calculate the number of paragraphs per batch.
const paragraphsPerBatch = Math.ceil(markdownElements.length / batchSize);
for (let batchIndex = 0; batchIndex < batchSize; batchIndex++) {
// Determine the slice of paragraphs for the current batch.
const start = batchIndex * paragraphsPerBatch;
const end = start + paragraphsPerBatch;
// Create a PreviewBatch with the relevant paragraphs.
const batchItems = paragraphsWithContext.slice(start, end)
.filter(p => !!p)
.map((p, index): BatchItemWithContext => ({
context: p.context.map(e => e ?? "").join(" "),
value: p.element ?? "",
index: start + index,
status: "in progress"
}));
const previewBatch: PreviewBatch = { batch: batchItems };
// Add the batch to the collection.
await previewBatchesCollection.add(previewBatch);
}
return { markdown: frontendMarkdown };
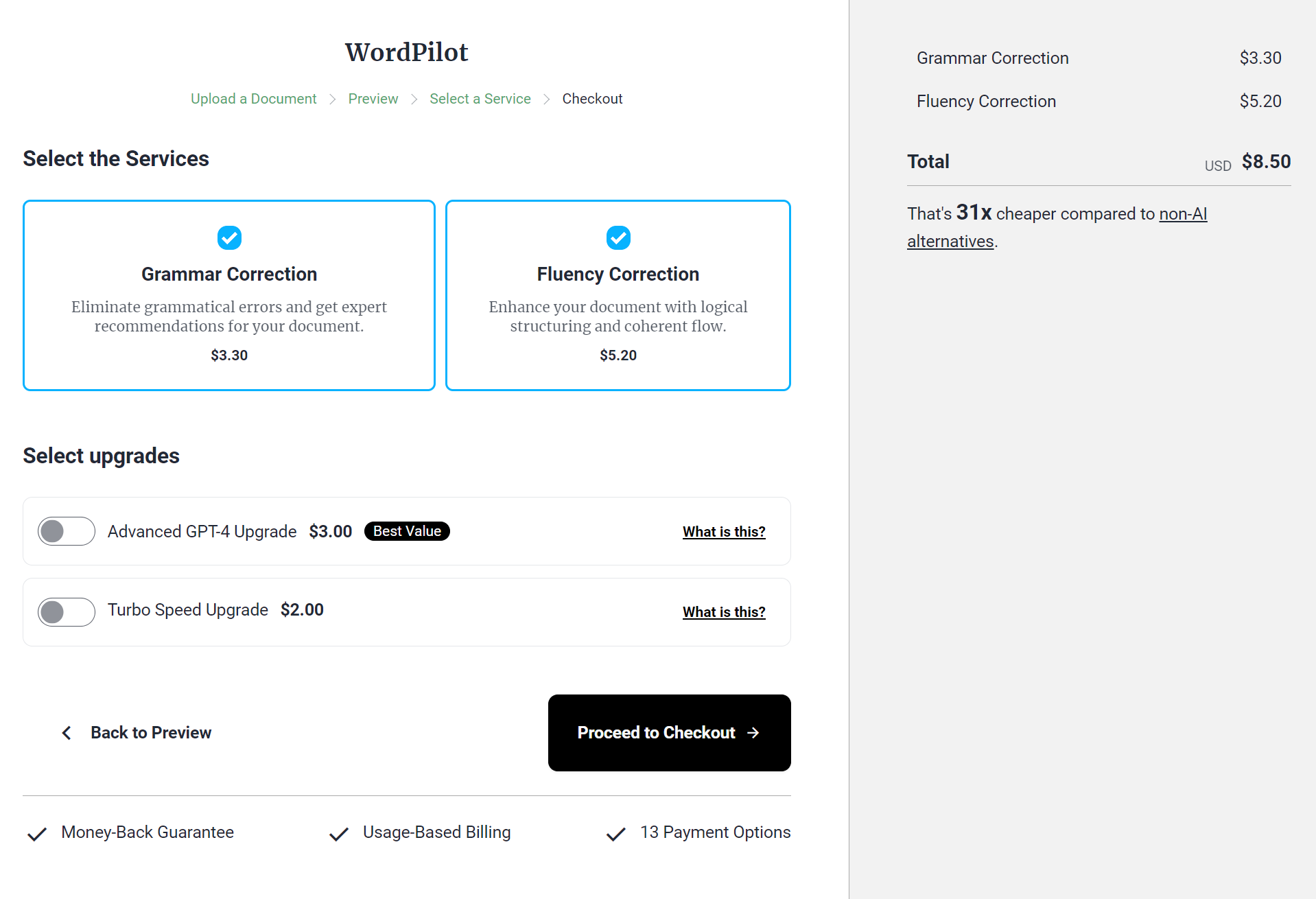
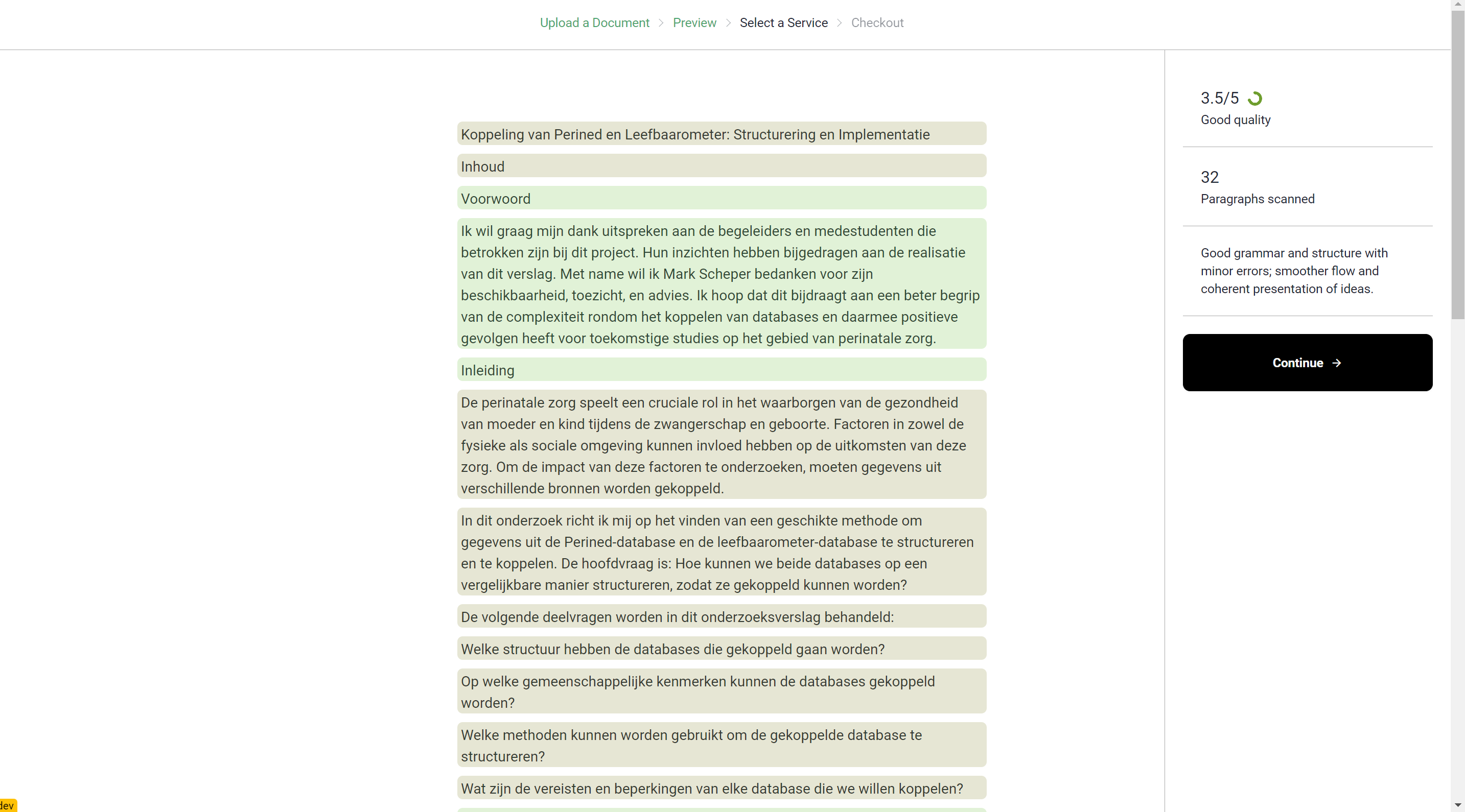
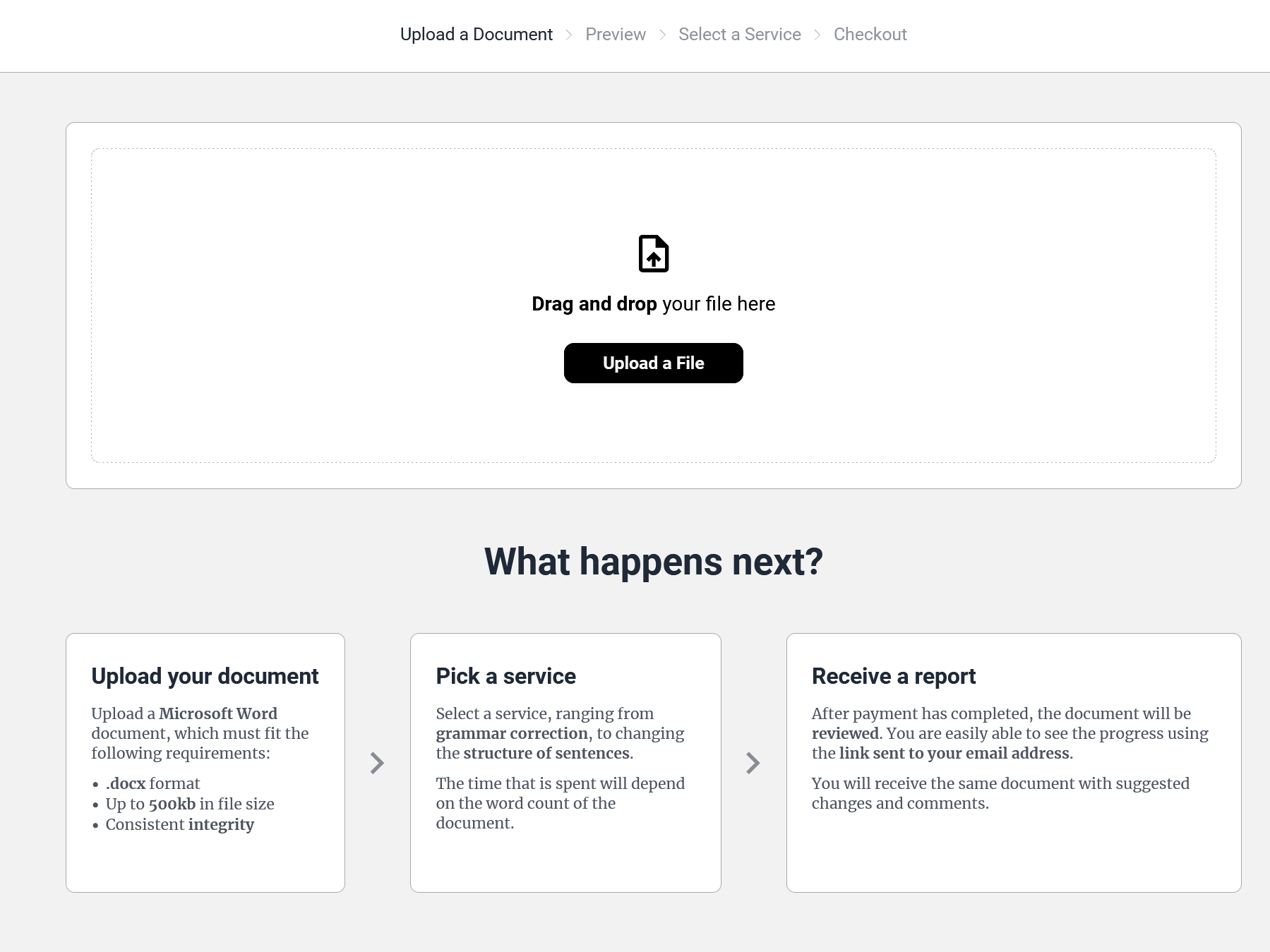
Checkout and Design
Given that a kubernetes cluster is expensive to run, I set the google cloud project to inactive. So sadly don't have any up-to-date screenshots of the design. But the following screenshots show the state of the design in an early stage